
大学院生の研究成果 ピックアップ
本研究科(旧 脳情報専攻も含む)の大学院生が公表した学術論文をピックアップして紹介します。
Reinforcement learning for discounted values often loses the goal in the application to animal learning, Yamaguchi Y, Sakai Y, Neural networks 35: 88-91, 2012
ヒトや動物は目先の利益にとらわれがちである。後で得られる大きな利益より、目先の小さな利益をしばしば選択する。動物のこのような行動特性は、2択の選択課題を繰り返し行うことで調べられている。一方を選ぶと、短い遅延の後、少量のエサが与えられる。もう一方を選ぶと、それより長い遅延の後、より多いエサが与えられる。どちらを選んでも次の試行が始まるまでの時間を一定にしてある。そのため、遅延の長さによらず単純にエサの量の多い方が得である。しかし、動物は、遅延時間のパターンによって、小さい方を選ぶことがある。客観的には損に見えるこのような行動特性は、動物が主観的に将来の利益の価値を割り引いており、主観的価値の高い方を選んだ結果である、と解釈されている。
遅延の分を割り引いた主観的価値を最大化するための学習の枠組みは、強化学習理論の中で「割引価値問題」として定式化されている。強化学習理論は、そのときの状態に応じて適切な行動を取れるように学習するための枠組みである。「割引価値問題」は割引状態価値という値を最大化する問題として定義されている。ある状態の割引状態価値とは、ある時点でその状態にいたとき、それ以後の各時点で得られる利益に遅延の割引の程度をかけながら積分した値の期待値として定義される。割引状態価値は様々な状態で定義される値であり、複数存在する。その全ての割引状態価値を最大化する問題が「割引価値問題」である。強化学習理論の中には「割引価値問題」以外の枠組みも多く存在するが、「割引価値問題」が最も広く分野を越えて広まっており、神経科学、神経経済学、心理学、認知科学において、行動データを解析するツールとして使われている。しかし、強化学習理論が前提としている条件(マルコフ決定過程)が成立しない場合に適用している例も多い。そのような場合にも「割引価値問題」が動物行動を理解する枠組みとして、本当に適しているのだろうか。この論文では、動物の行動実験によく用いられるような単純な選択課題でも、強化学習理論が前提としている条件が崩れ、「割引価値問題」の問題設定自身が崩壊し、最適な行動が存在しなくなる、ということを指摘した。
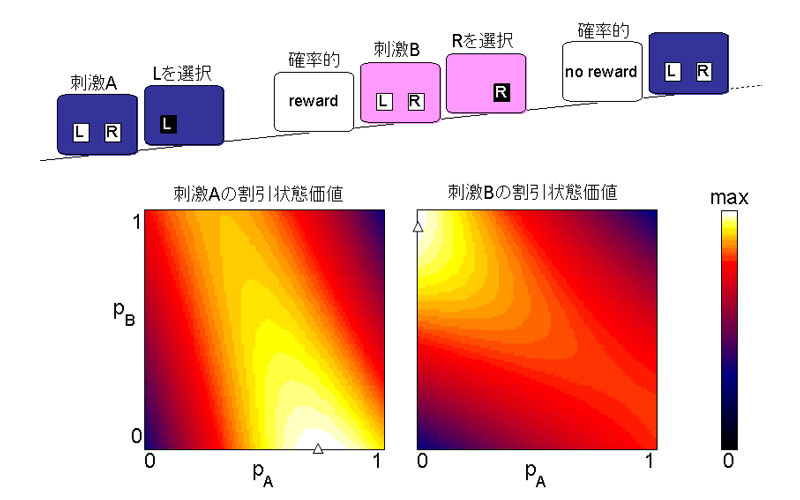
上図のように感覚刺激AもしくはBが提示され、左右にあるLかRのボタンを選ぶと、確率的に報酬が与えられる、という試行を繰り返す単純な選択課題を考える。このとき、動物が与えられる感覚刺激{A or B}を状態として設定している場合を考える。AのときにLボタンを選ぶ確率をpAとし、BのときにLボタンを選ぶ確率をpBとすると、それぞれRボタンを選ぶ確率は1-pA, 1-pBで、(pA,pB)の組で行動選択の仕方が定まる。このとき、AとBの割引状態価値を両方とも最大化するような(pA,pB)の組にたどり着くことが、「割引価値問題」における目標となる。しかし、状態Aの割引状態価値は、その後訪れた状態Bでどちらを選ぶかに依存する。したがって、状態Aの割引状態価値を最大化しようとすると、状態Bの割引状態価値が最大でなくなる、というようなことが一般には起こりうる。 報酬や感覚刺激の提示を決める確率ルールとして、あるルールを設定したときに、(pA,pB)の関数として、AとBの割引状態価値を求め、擬似カラーで図に示した。Aの割引状態価値が最大になる(pA,pB)とBの割引状態価値が最大になる(pA,pB)が大きく異なっており、両方を最大化するような行動選択の仕方が存在しないことがわかる。「割引価値問題」の解が存在せず、学習の目標を失っていることがわかる。「割引価値問題」の枠組みを使うと、一体、何のために学習しているのかわからず、学習行動の理解の枠組みとして崩壊していることを示している。
この欠陥を解決する糸口として、遅延期間に待っている間の割引の効果と試行をまたぐときの割引の効果は異なるという知見に注目した。この両者をつなぐため、イベント発生によって進む離散的な時間ステップを導入し、そのイベント間の実間隔は変動することを想定した。その上で、従来の「割引価値問題」の欠陥を解決するため、最大化すべき値は1つであるような問題設定で、動物の行動を再現するものは何か、検討した。その結果、イベントの間は連続的な実時間に従って従来の遅延時間に対するような割引が起こり、イベントをまたいで時間ステップが進むときには、掛け算で割引の効果が起こるような主観的価値を定義すると、1試行内の割引の効果も試行をまたいだ割引の効果も再現することがわかった。この問題設定は、最大化すべき値は1つであるため、どんな状況でも最適行動は存在し、そのための学習を評価することが可能である。
「割引価値問題」に則った枠組みは分野を越えて広まっている。この論文は、適用条件を越えた安易な適用に対して警鐘を鳴らすと共に、破綻しない適切な枠組みを提案している。






