
論文紹介
脳科学研究科に所属する教員による主な研究成果をプレスリリースした論文を中心に紹介します。
- 木村 實 教授 他
Dopamine neurons learn to encode the long-term value of multiple future rewards. Enomoto K, Matsumoto N, Nakai S, Satoh T, Sato TK, Ueda Y, Inokawa H, Haruno M, Kimura M. Proc Natl Acad Sci U S A. 2011 Sep 13;108(37):15462-7
玉川大学脳科学研究所の榎本一紀(えのもとかずき)研究員と木村實(きむらみのる)教授らは、目標達成のために意志決定や行動をする上で、脳のドーパミン細胞の放電活動が、将来得られると予測される報酬の価値を計算していることを世界で初めて実証した。意志決定の脳の作動原理解明につながる成果である。この成果は、米国科学アカデミー紀要オンライン版に2011年9月6日(日本時間)に掲載された。
1.研究の概要
試験問題に回答する場合には、いきなり第一問から取り組むのではなく、すべての問いに目を通し、まず容易な問いから回答を仕上げて余裕をもった上で難解な問題に挑戦する。テニスやサッカーなどの試合においては、経験の浅いプレーヤーは最初から全力で戦い、試合の途中で息切れがしてしまうこともあるが、経験を積んだプレーヤーは、勝負どころである試合の中盤で優位に立つように配分を考えて戦う。他にも、囲碁や将棋における現在の局面から最終的に勝利するための戦略決定や、株取引での将来予測、ダイエット中の目標設定と生活改善計画など、私たちは、目標達成に向けて様々な選択肢を選ぶ場合に、予想される報酬(食料・金銭、名誉や達成感など)を考えて意志決定をしている。「朝三暮四」の故事にあるように、目先の利益だけにとらわれて振る舞えば、将来大きな利益を得ることはできない。ゲームに勝ち、富を築き、またダイエットに成功するためにも、目標に照らし合わせて二手先、三手先に有利な行動を選ぶことが必要である。
中脳にあるドーパミン細胞は、選択肢のもつ価値(報酬の量と確率)の予測と、報酬予測誤差(選択して得られた実際の報酬と予測との差)を放電活動によって表現することが知られている。しかし、様々な行動を組み立てて目標を達成する場合に、途中で得られる報酬を予測するかどうかは分っていなかった。私たちは、複数の行動を行なって報酬を得る過程で、脳のドーパミン細胞が、将来得られると予測される報酬の価値を計算していることを見出した。この研究によって、強化学習理論(試行錯誤で目標を達成する際に、進歩・後退する行動の価値を上げ下げし、価値の合計を最大にする目標を実現する)の最も基本的な役割を、脳のドーパミン細胞が担っていることが立証された。これは意志決定の脳の作動原理解明につながる成果である。
2.研究の内容
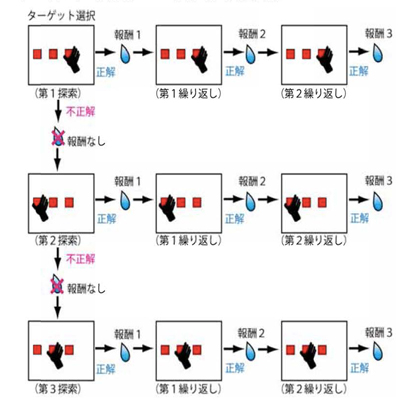
図1:合計3回の報酬を得る行動選択課題
複数の選択肢から1つの正解を探すために一連の意志決定とボタン押し行動をおこなって、合計3回の報酬を得ることを目標とする課題(図1)を実験動物である日本ザルに学習させた。この課題では、まず、試行錯誤によって、3つの選択肢から1つの正解を探す(第1探索)。選んだ選択肢が正解だった場合は、報酬(ジュース)が得られるが、不正解だった場合は、報酬は得られず、次のステップ(第2探索)で他の2つの選択肢から1つを選ぶ。それでも不正解ならば、さらに次のステップ(第3探索)で、残った1つの選択肢を選ぶ。一度正解すると、続く2回の試行では、同じ選択肢を選ぶことで、2回続けて報酬が得られる(第1・第2繰り返し試行)。すなわち、第1探索では三分の一、第2探索では二分の一、第3探索と繰り返し試行では、ほぼ100%の確率で報酬が得られることになる。
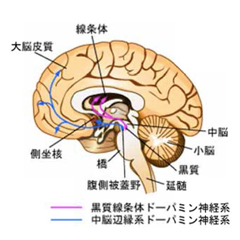
図2:中脳ドーパミン細胞とその放電活動の記録
この課題を十分学習させた後、脳のドーパミン細胞(図2)の放電活動を調べた。各試行開始の合図に対する応答は、第1探索から第3探索にかけて、報酬確率が上がると共に大きくなったが、第1繰り返し、第2繰り返し試行へと進むと、報酬確率はどちらもほぼ100%であるにもかかわらず(図3、点線のプロット)、応答は逆に小さくなった(図3、棒グラフ)。
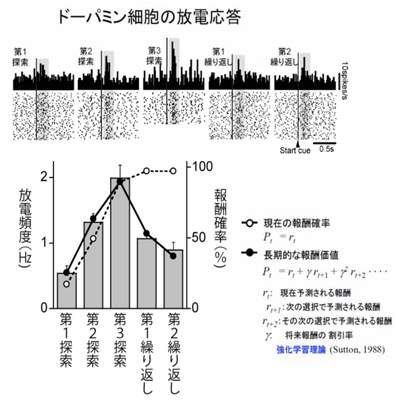
図3:ドーパミン細胞の放電活動
このことは、ドーパミン細胞の応答が、各試行での報酬1回分だけの確率(予測)を表現するのではなく、探索試行で1回、繰り返し試行で2回、合計3回分の報酬の予測を表現していることを示している。つまり、探索試行では3回の総報酬の1回分の報酬を得るための確率を、第1繰り返し試行ではすでに1回分の報酬を得たので残り2回分、第2繰り返し試行では過去に2回報酬を得ているので残り1回分の報酬情報が表現されている。したがって、ドーパミン細胞の放電活動は、3回分の報酬を得るための最初から最後までの一連の試行における価値(報酬の量と確率)を表現していることが分かった(図3、実線のプロット )。また、課題の学習が不十分な状態ではこのような活動は見られないので、探索試行で1回、繰り返し試行で2回、合計3回分の報酬が得られるという長期的な収益予測を、ドーパミン細胞を中心とする脳の神経回路が学習によって獲得したものと考えられる。
3.研究の成果と展望
私たちの研究によって、ドーパミン細胞の活動は、強化学習理論が唱えるように、目標に到達するまでに期待される二手先、三手先の複数の報酬価値を表現することが明らかになった。この成果は、目先の利益だけを優先するのでなく、長期的な収益予測に基づいて意志決定と行動選択を行うという、意志決定の脳の作動原理解明につながる里程標となると期待される。
また、たばこ、麻薬などへの依存やギャンブル依存などは、ドーパミン細胞を中心とする脳の報酬系神経回路の異常なはたらきを通して生じると考えられており、今後更に目標達成までの収益予測を計算するドーパミン細胞と脳の報酬系神経回路のメカニズムの理解が進むことによって、薬物やギャンブル依存を含む社会性・社会性行動異常の病態の解明や治療法の開発にもつながる可能性が期待される。
4.謝辞
この研究成果は、文部科学省科学研究費補助金による支援、および脳科学研究戦略推進プログラム「社会的行動を支える脳基盤の計測・支援技術の開発」の一環として得られたものである。






